
Latent Diffusion Model & Stable Diffusion
背景
谈到LDM,就不得不提大名鼎鼎的Stable Diffusion了。其实SD就是一个基于LDM的text-to-image模型,用LAION-5B数据集进行训练的大模型。
为什么他会这么火?其实和他的一些优点有关:
- 训练效率非常高、成本极低
- 支持高分辨率
- 支持多模态
这些都得益于LDM在潜在表示空间中diffusion,而不是对pixel level做diffusion
原理
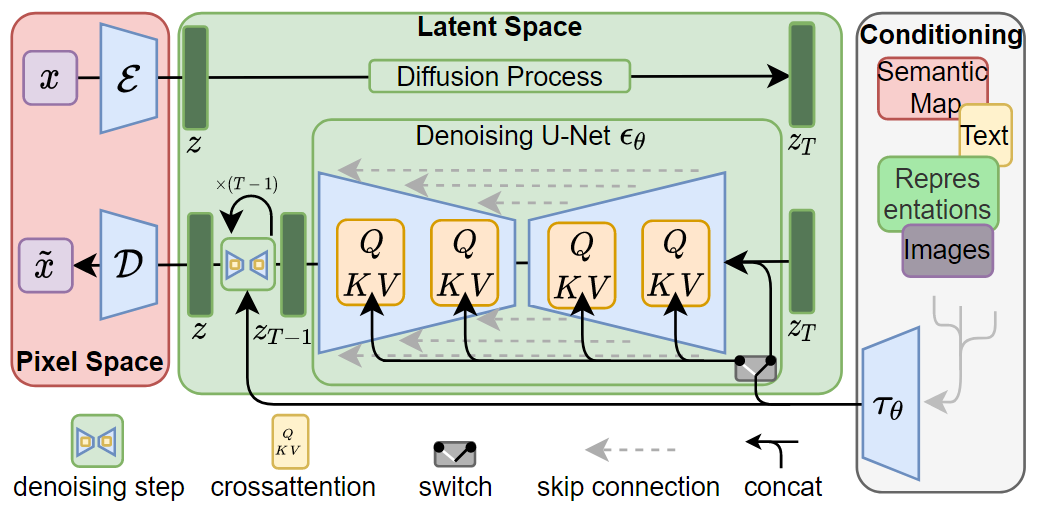
LDM的整体框架如图所示,首先训练好一个AutoEncoder,包括一个编码器 和一个解码器 。这样一来,我们就可以利用编码器对图片进行压缩,然后在潜在表示空间上做diffusion操作,最后我们再用解码器恢复到原始像素空间即可,论文将这个方法称之为感知压缩(Perceptual Compression)。在潜在表示空间上做diffusion操作其主要过程和标准的扩散模型没有太大的区别,只是引入了条件机制。最终通过cross-attention的方式来实现多模态训练,使得条件图片生成任务也可以实现。
三个关键技术点:
- Perceptual Image Compression(图片感知压缩)
- 下采样因子大小为 ,实验表示 可以比较好的平衡压缩效率与视觉感知效果
- Latent Diffusion Models(就是一个普通的DM)
- Conditioning Mechanisms(条件机制)
- 条件时序去噪自编码器
- 将上面这个cross-attention层加入到UNet中,来融入控制信息,其中 是一个领域专用编码器
Stable Diffusion
stable diffusion(SD)相比 latent diffusion model(LDM)主要有以下几点改进:
- 训练数据: LDM用laion-400M数据集训练,而SD用laion-2B-en数据集训练,后者用了更多的训练数据,且采用了数据筛选来提升数据质量,比如去掉有水印的图像以及选择美学评分较高的图像。
- text encoder: LDM采用一个随机初始化的transformer来编码text,而SD采用一个预训练好的CLIP text encoder来编码text
- 训练尺寸: LDM分辨率为256x256,而LDM先在256x256分辨率上预训练,然后再在512x512分辨率上finetune。
参考资料
[1] High-Resolution Image Synthesis with Latent Diffusion Models
[2] Latent Diffusion Models论文解读 - 知乎 (zhihu.com)
[3] stable diffusion相比于latent diffusion有哪些改进? - 知乎 (zhihu.com)