Score-based Model via Langevin Dynamics
根据能量模型的理论,任意一个概率分布都可以用一个更通用的形式来表示
p θ ( x ) = exp ( − E θ ( x ) ) Z ( θ ) p_\theta(x)=\dfrac{\exp(-\mathbb{E}_\theta(x))}{Z(\theta)} p θ ( x ) = Z ( θ ) exp ( − E θ ( x ) )
其中,分母是归一化的配分函数
最直接的优化方法就是求MLE(Maximum Likelihood Expectation),但是由于Z的存在,无法直接优化,但是又可以利用MCMC的方法估计对数似然的梯度,得到
∇ θ log p θ ( x ) = − ∇ θ E θ ( x ) − ∇ θ log ( Z θ ) \nabla_\theta\log p_\theta(x)= - \nabla_\theta\mathbb{E}_\theta(x)-\nabla_\theta\log(Z_\theta) ∇ θ log p θ ( x ) = − ∇ θ E θ ( x ) − ∇ θ log ( Z θ )
第一项可以直接梯度下降,第二项可以展开得到一个无偏的单样本估计:
∇ θ log ( Z θ ) ≃ − ∇ θ E θ ( x ~ ) , x ~ ∼ p θ ( x ) \nabla_\theta\log(Z_\theta)\simeq- \nabla_\theta\mathbb{E}_\theta(\tilde x),\ \tilde x \sim p_\theta(x) ∇ θ log ( Z θ ) ≃ − ∇ θ E θ ( x ~ ) , x ~ ∼ p θ ( x )
什么是无偏估计呢?就是每个样本的概率都一样。
而这个样本是从能量模型构建的分布中采样出来的,所以只要可以从模型中采样,就可以得到这一项,因此两项都可以求。但是采样这件事本身不是很简单,宋飏博士提到了两种采样方法,Langevin MCMC和Hamiltonian Monte Carlo,都利用了对数似然对样本的梯度就是对能量函数 E \mathbb{E} E
∇ x log p θ ( x ) = − ∇ x E θ ( x ) − ∇ x log ( Z θ ) = − ∇ x E θ ( x ) \nabla_x \log p_\theta(x)= - \nabla_x \mathbb{E}_\theta(x)-\nabla_x\log(Z_\theta)=- \nabla_x \mathbb{E}_\theta(x) ∇ x log p θ ( x ) = − ∇ x E θ ( x ) − ∇ x log ( Z θ ) = − ∇ x E θ ( x )
中间式中,由于第二项与x无关,所以梯度为0。
然后根据朗之万动力学采样(Langevin-MCMC)
x k + 1 ← x k + ϵ 2 2 ∇ x log p θ ( x k ) + ϵ z k , k = 0 , 1 , . . . , K − 1 x^{k+1}\leftarrow x^k+\dfrac{\epsilon^2}{2}\nabla_x\log p_\theta(x^k)+\epsilon z^k, k=0,1,...,K-1 x k + 1 ← x k + 2 ϵ 2 ∇ x log p θ ( x k ) + ϵ z k , k = 0 , 1 , . . . , K − 1
当 ϵ \epsilon ϵ K K K p θ p_\theta p θ
这样我们就可以通过估计 p θ p_\theta p θ x x x
总结一下,我们对能量模型参数的每一次随机梯度更新,都需要使用MCMC来近似从分布里采样,来估计梯度的计算。这样做会需要大量样本,从而带来非常大的计算量。
用神经网络来拟合score,就是score matching,优化目标为
D F ( p ( x ) ∥ p θ ( x ) ) = E p [ ∣ ∣ ∇ x log p ( x ) − s θ ( x ) ) ∣ ∣ 2 2 ] D_F(p(x)\parallel p_\theta(x))=\mathbb{E}_{p}[||\nabla_x \log p(x)-s_\theta(x))||^2_2] D F ( p ( x ) ∥ p θ ( x ) ) = E p [ ∣ ∣ ∇ x log p ( x ) − s θ ( x ) ) ∣ ∣ 2 2 ]
Score matching 的目标就是使得真实数据分布对输入x的对数似然的梯度(score)和我们所建模的近似分布的score一致。然后,根据一阶导处处相等,且概率密度函数积分都为1,所以两个数据分布一致。
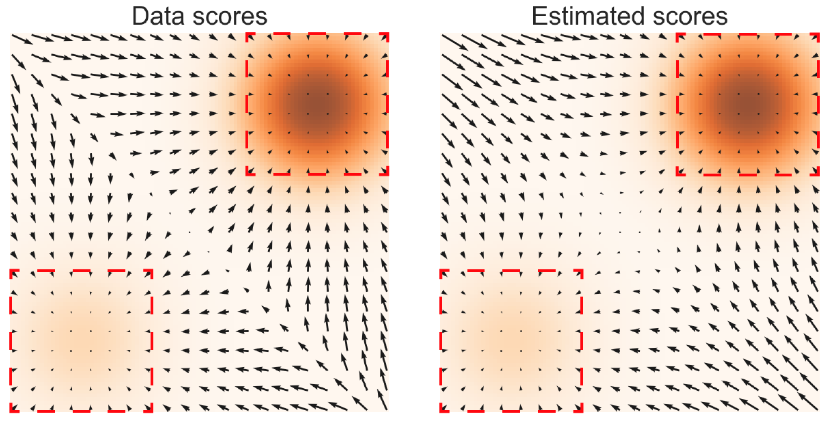
一个对score比较直观的解释就是“矢量场”,也是宋飏博士在论文中借用的可视化方式。
两个焦点意味着数据分布中心,而位于场的其余位置的数据可以通过梯度下降的方式收敛到数据分布的高概率密度区域。
但是哪怕我们直接将能量模型建模成score,然后根据训练好的能量模型的score来进行MCMC采样,也依然逃不过对分布的计算。但有大量的工作让我们可以直接计算score-matching,而不需要计算真实数据分布。同时这些方法还足够快,只涉及到一阶导数的计算。因此,效率会大大提高。
利用神经网络近似score function,然后使用朗之万动力学采样目标分布的样本,但是简单地使用上面的score matching方案会有两个问题:
大部分我们希望拟合的数据(比如图像)在高维空间里表现为低维流形。而大部分采样的点不落在低维流形上则其概率为零,对零概率的点取对数(score的定义是logP(x))无意义。
score function的优化目标是个L2范数的期望,而对于低密度的区域该期望因无法得到足够多的样本来监督训练,其准确度也不高。该问题和以上的低维流形问题一起加剧了采样结果的不理想情况。
而根据宋飏博士的论文,以上两个问题都会被往数据里添加高斯噪声所解决。
高斯噪声的定义域是整个参数空间,所以对原数据添加高斯噪声解决了低维流形的零概率问题。
添加大量的高斯噪声实质上扩展了分布里的各个众数的范围,使得数据分布里的低概率区得到了更多监督信号。
但是高斯噪声的尺度选择不是个简单的问题,加过大的噪声虽然会覆盖更多的低概率空间,但同时也会剧烈地改变原数据分布,但过小的噪声又会使得低概率空间的监督信号不足,尽管小噪声可以获得对原数据分布更好的近似。
而作者最终采用的方案是添加一系列不同尺度的噪声,并训练一个条件于噪声大小的score matching网络(noise-conditioned-score-based-model)对他们进行拟合。
使用NCSN学习score function,然后使用 annealed Langevin dynamics 采样
定义一组几格级数序列(等比数列){ σ i } i = 1 L \{\sigma_i\}_{i=1}^L { σ i } i = 1 L σ i > 0 \sigma_i>0 σ i > 0 σ 1 σ 2 = σ 2 σ 3 = ⋯ = σ L − 1 σ L > 1 \dfrac{\sigma_1}{\sigma_2}=\dfrac{\sigma_2}{\sigma_3}=\cdots=\dfrac{\sigma_{L-1}}{\sigma_{L}}>1 σ 2 σ 1 = σ 3 σ 2 = ⋯ = σ L σ L − 1 > 1 q σ ( x ) = ∫ p ( x ) N ( x ∣ t , σ 2 I ) d t q_\sigma(x)=\int p(x)\mathcal{N}(x|t,\sigma^2\mathbf{I})dt q σ ( x ) = ∫ p ( x ) N ( x ∣ t , σ 2 I ) d t
加入噪声扰动后的数据分布为 q σ ( x ~ ∣ x ) = N ( x ~ ∣ x , σ 2 I ) q_\sigma(\tilde x|x)=\mathcal{N}(\tilde x|x,\sigma^2\mathbf{I}) q σ ( x ~ ∣ x ) = N ( x ~ ∣ x , σ 2 I )
然而 x ~ = x + σ ϵ \tilde x = x + \sigma\epsilon x ~ = x + σ ϵ
∇ x ~ log [ q σ ( x ~ ∣ x ) ] = − ϵ σ = − 1 1 − α ˉ t ϵ \nabla_{\tilde x} \log[q_\sigma(\tilde x | x)]=-\dfrac{\epsilon}{\sigma}=-\dfrac{1}{\sqrt{1-\bar\alpha_t}}\epsilon ∇ x ~ log [ q σ ( x ~ ∣ x ) ] = − σ ϵ = − 1 − α ˉ t 1 ϵ
这其实是make sense的,因为梯度更新的方向是噪声的反方向,实质上等价于去噪的过程,所以这也是score matching和DDPM的联系,在损失函数上也是一致的。
这里引用[2]的证明:
根据Tweedie's Formula,对于一个高斯变量 z ∼ N ( z ; μ z , Σ z ) z\sim\mathcal{N}(z;\mu_z,\Sigma_z) z ∼ N ( z ; μ z , Σ z )
μ z = z + Σ z ∇ z log p ( z ) \mu_z = z + \Sigma_z\nabla_z\log p(z) μ z = z + Σ z ∇ z log p ( z )
套用到前向过程 x t ∼ q ( x t ∣ x 0 ) = N ( x t ; α ˉ t x 0 , ( 1 − α ˉ t ) I ) x_t\sim q(x_t|x_0)=\mathcal{N}(x_t;\sqrt{\bar\alpha_t}x_0,(1-\bar\alpha_t)\mathbf{I}) x t ∼ q ( x t ∣ x 0 ) = N ( x t ; α ˉ t x 0 , ( 1 − α ˉ t ) I )
α ˉ t x 0 = x t + ( 1 − α ˉ t ) ∇ x t log p ( x t ) \sqrt{\bar\alpha_t}x_0=x_t+(1-\bar\alpha_t)\nabla_{x_t}\log p(x_t) α ˉ t x 0 = x t + ( 1 − α ˉ t ) ∇ x t log p ( x t )
做一下关于 x 0 x_0 x 0
x 0 = x t + ( 1 − α ˉ t ) ∇ x t log p ( x t ) α ˉ t = x t − 1 − α ˉ t ϵ t α ˉ t → ∇ x t log p ( x t ) = − ϵ t 1 − α ˉ t x_0=\dfrac{x_t+(1-\bar\alpha_t)\nabla_{x_t}\log p(x_t)}{\sqrt{\bar\alpha_t}}=\dfrac{x_t-\sqrt{1-\bar\alpha_t}\epsilon_t}{\sqrt{\bar\alpha_t}} \rightarrow \nabla_{x_t}\log p(x_t)=-\dfrac{\epsilon_t}{\sqrt{1-\bar\alpha_t}} x 0 = α ˉ t x t + ( 1 − α ˉ t ) ∇ x t log p ( x t ) = α ˉ t x t − 1 − α ˉ t ϵ t → ∇ x t log p ( x t ) = − 1 − α ˉ t ϵ t
代入到DDPM中推导出来的 μ q \mu_q μ q
μ q = 1 α t x t + 1 − α t α t ∇ x t log p ( x t ) \mu_q=\dfrac{1}{\sqrt{\alpha_t}}x_t+\dfrac{1-\alpha_t}{\sqrt{\alpha_t}}\nabla_{x_t}\log p(x_t) μ q = α t 1 x t + α t 1 − α t ∇ x t log p ( x t )
类似地,逆向过程可以建模为
μ θ = 1 α t x t + 1 − α t α t s θ ( x t , t ) \mu_\theta=\dfrac{1}{\sqrt{\alpha_t}}x_t+\dfrac{1-\alpha_t}{\sqrt{\alpha_t}}s_\theta(x_t,t) μ θ = α t 1 x t + α t 1 − α t s θ ( x t , t )
这样DDPM中的优化目标和score matching的优化目标其实就是一致的了。
但是对于训练目标
l ( θ , σ ) = E p σ ( x ) [ ∣ ∣ x ~ − x σ 2 + s θ ( x ) ) ∣ ∣ 2 2 ] l(\theta,\sigma)=\mathbb{E}_{p_{\sigma}(x)}[|| \dfrac{\tilde x-x}{\sigma^2} + s_\theta(x))||^2_2] l ( θ , σ ) = E p σ ( x ) [ ∣ ∣ σ 2 x ~ − x + s θ ( x ) ) ∣ ∣ 2 2 ]
其关于 σ \sigma σ 1 σ 2 \dfrac{1}{\sigma^2} σ 2 1 σ \sigma σ σ 2 \sigma^2 σ 2
L ( θ , { σ i } i = 1 L ) = 1 L ∑ i = 1 L λ ( σ i ) l ( θ , σ i ) , λ ( σ i ) = σ i 2 L(\theta,\{\sigma_i\}_{i=1}^L)=\dfrac{1}{L}\sum\limits_{i=1}^{L}\lambda(\sigma_i)l(\theta,\sigma_i), \ \lambda(\sigma_i)=\sigma_i^2 L ( θ , { σ i } i = 1 L ) = L 1 i = 1 ∑ L λ ( σ i ) l ( θ , σ i ) , λ ( σ i ) = σ i 2
在这种训练方式下,只要预先设定好 { σ i } i = 1 L \{\sigma_i\}_{i=1}^L { σ i } i = 1 L σ i \sigma_i σ i ϵ \epsilon ϵ x ~ = x + σ i ϵ \tilde x=x+\sigma_i\epsilon x ~ = x + σ i ϵ x ~ \tilde x x ~ σ i \sigma_i σ i s θ ( x ~ , σ i ) s_\theta(\tilde x,\sigma_i) s θ ( x ~ , σ i )
具体算法流程如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 def anneal_dsm_score_estimation (scorenet, samples, labels, sigmas, anneal_power=2. ):0 ], *([1 ] * len (samples.shape[1 :])))1 / (used_sigmas ** 2 ) * (perturbed_samples - samples)0 ], -1 )0 ], -1 )1 / 2. * ((scores - target) ** 2 ).sum (dim=-1 ) * used_sigmas.squeeze() ** anneal_powerreturn loss.mean(dim=0 )
代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 def anneal_Langevin_dynamics (self, x_mod, scorenet, sigmas, n_steps_each=100 , step_lr=0.00002 ):with torch.no_grad():for c, sigma in tqdm.tqdm(enumerate (sigmas), total=len (sigmas), desc='annealed Langevin dynamics sampling' ):0 ], device=x_mod.device) * c1 ]) ** 2 for s in range (n_steps_each):0.0 , 1.0 ).to('cpu' ))2 )return images
[0] Generative Modeling by Estimating Gradients of the Data Distribution
[1] 一文解释 经验贝叶斯估计, Tweedie's formula - 知乎 (zhihu.com)
[2] 一文解释 Diffusion Model (二) Score-based SDE 理论推导 - 知乎 (zhihu.com)
[3] Generative Modeling by Estimating Gradients of the Data Distribution | Yang Song (yang-song.net)
[4] Score Matching 系列 (一) Non-normalized 模型估計 | 棒棒生 (bobondemon.github.io)
[5] 基于分数的生成模型(Score-based Generative Model ) - 知乎 (zhihu.com)
[6] 生成扩散模型漫谈(五):一般框架之SDE篇 - 科学空间|Scientific Spaces
[7] 扩散模型与能量模型,Score-Matching和SDE,ODE的关系 - 知乎 (zhihu.com)
[8] How to Train Your Energy-Based Models
[9] 图像生成别只知道扩散模型(Diffusion Models),还有基于梯度去噪的分数模型:NCSN(Noise Conditional Score Networks) - 知乎 (zhihu.com)